
前两天发了用Python脚本爬了50G的tumblr视频图片:文章源自技术奇点-https://www.xerer.com/archives/18830.html
利用python爬虫搜索tumblr视频图片资源(2017_02.rar torrent解压密码)文章源自技术奇点-https://www.xerer.com/archives/18830.html
爬虫工具是在GitHub中找的Python代码,所以我也抽空在GitHub里搜到了几个Python的爬虫源码,想自己也爬一下自己关注的那些tumblr账号,从安装Python环境,到执行脚本,期间经历各种挫折,先是下载的Python3.6版本,无奈代码报错,后来换了2.7版本,倒是不报错了,可惜执行后无任何结果,不知道到底哪里有问题,只能怨自己不懂Python。文章源自技术奇点-https://www.xerer.com/archives/18830.html
其实很早之前就有了下载tumblr视频的想法,一直没找到现成的工具,也没什么时间自己搞,所以每次都只能在线看,直到看了那位大大的帖子,再到自己没搞定Python,所以下决心自己搞个下载工具。当然为了发帖不违规,这个帖只说一下自己搞下载工具的过程,如果需要工具的可私信我,就不在这发下载链接了。文章源自技术奇点-https://www.xerer.com/archives/18830.html
通过分析下载的那几个Python脚本代码后,给我提供了一些很好的思路。这几个Python脚本,有一个是自己先用txt定义一些tumblr账号,用逗号隔开,然后脚本自动去这些tumblr账号里识别视频链接,找到视频下载地址,最后下载到本地。还有一个是只填写一个tumblr账号,然后它根据这个tumblr账号识别视频链接、找到下载地址再下载到本地,这时还没完,它还会识别这些视频是否是转发自其他tumblr账号,然后再添加转发来源账号,再进行视频下载,一个账号一个账号的跑,无限的跑下去,这正是叫爬虫的原因。文章源自技术奇点-https://www.xerer.com/archives/18830.html
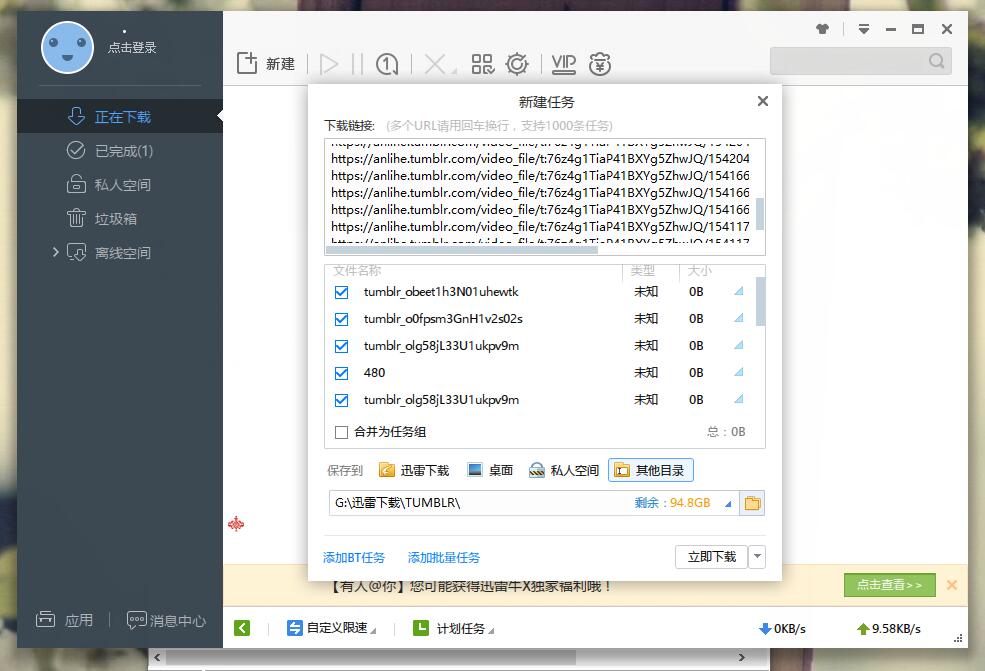
最终我确定了这个下载工具的需求,由于不想搞那么复杂,所以核心需求就是,输入完想下载视频的tumblr账号,点击确认后,把该账号下所有发过的视频链接全部识别出来(不管有多少页),最后识别出下载地址就完了,为什么不在工具里加下载功能呢,因为下载这个事还是让专业的去干吧,我只需要一批下载地址就好了,有了它们,在迅雷里添加任务就可以了,迅雷怎么说也比自己写的的下载功能强吧。文章源自技术奇点-https://www.xerer.com/archives/18830.html
需求既然已经明确了,那话不多说,直接开搞。文章源自技术奇点-https://www.xerer.com/archives/18830.html
首先先分析一下tumblr账号的视频链接的命名规律,找到规律后,就可以在网页源代码中把他们全部提取出来了。我们随便进去一个tumblr账号,例如 xxxx.tumblr.com(xxxx是账号名称),网页加载完毕后,随便找到一个视频,右键-属性,然后就可以看到视频链接了,他们大概是这样的:
複製代碼
”https://www.tumblr.com/video/账号名/12位的数字/3位的数字/”
用正则表达式匹配就可以把他们全部匹配出来了,正则表达式可以这么写:
複製代碼
“https://www.tumblr.com/video/.*?/\d+/\d+/”; .*?代表匹配任意字符,\d匹配数字 +匹配1个或多个。\d+就是匹配多个数字,注:只有一个反斜线,两个是因为有一个是论坛的转义符。
那这个链接是视频的下载地址吗,其实并不是,在网页中直接输入这个链接,可以正常播放,但并不能放到迅雷里下载。 下载地址在哪呢,其实在这个链接返回的信息里面。下一步就是访问这个链接,然后在返回的网页源码中,找到视频下载地址,他们是这样的:
複製代碼
https://账号名.tumblr.com/video_file/t:igK72bq7btAh-4IqriDnuQ/157612196002/tumblr_oltdbePLrt1vmsime/480
直接正则表达式匹配:
複製代碼
”https://账号名.tumblr.com/video_file/t:.*?”,不管t:后面是什么,全部都匹配出来,直到有双引号时停止。
到这里,基本已经实现了识别视频链接和下载地址的目的,然而这并没有结束,下一步就是完成识别完第一页之后,自动跳到第二页去识别,然后一页一页直到最后一页。这里我的做法是,分析网页源代码中下一页的链接,它们是这样的: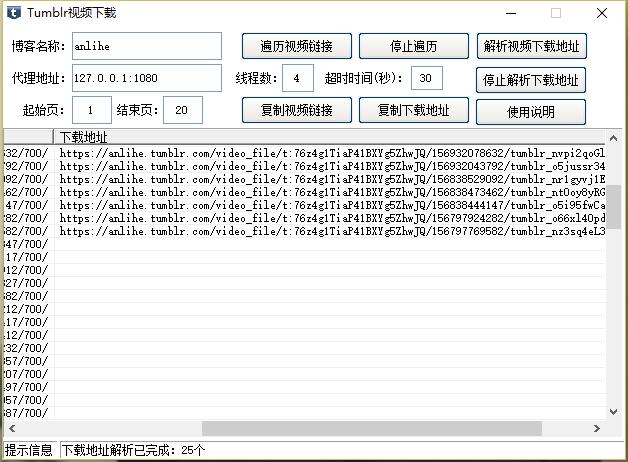
複製代碼
xxxx.tumblr.com/page/2(/3,/4,/5),page/几,就是第几页
最后一页的网页源码中没有下一页的信息,只有上一页的信息,所以等到这种情况发生时,就说明全部识别完毕了,代码就是嵌套循环,判断是否有/page/X。最后就是复制功能,把识别到视频地址或下载地址复制到剪贴板,粘贴到迅雷中下载就搞定了。
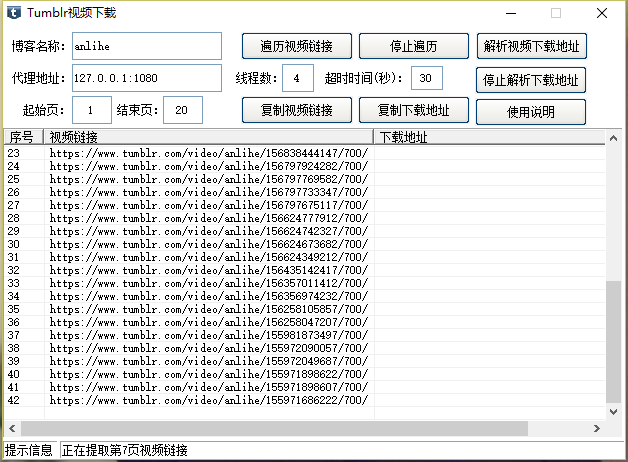
最后附上成果截图:文章源自技术奇点-https://www.xerer.com/archives/18830.html
 文章源自技术奇点-https://www.xerer.com/archives/18830.html
文章源自技术奇点-https://www.xerer.com/archives/18830.html
有些人的tumblr里面视频真的多,昨天简单的运行了一会,100多页还没完,那时都已经1000多条视频链接了,全部搞完估计得几千条,全部下载了估计硬盘真的吃不消。好了,tumblr视频下载终于可以告一段落了。
-----------------------------------------------------------------------------------
最新更新内容:
上面刚说告一段落,但还是没忍住,下午又找到一个新的方法获取视频链接,而且速度比第一个版本快几倍不止。原因是调用了tumblr的API接口:
複製代碼
http://账号名.tumblr.com/api/read/json?start=0&num=50文章源自技术奇点-https://www.xerer.com/archives/18830.html
这样一次可以获取50条信息,而第一个版本只能获取15条,速度就在这体现出来了。
重新开搞,终于在晚上又搞定一个版本:文章源自技术奇点-https://www.xerer.com/archives/18830.html
如果要下载工具,特征码是1dEYbtYD 密码: pe9f,给个提醒是百度的。下载视频时,下载工具也需要挂代理,迅雷和IDM等都有代理功能,设置一下就可以了。文章源自技术奇点-https://www.xerer.com/archives/18830.html

2017/04/19 08:59 1F
[email protected]求文件