
最近闲着无聊接触了点python爬虫,在著名的Github代码网站上搜索了下爬虫工具发现有很多有意思的东西,下了一个tumblr爬虫,通过用户ID下载其分享的所有视频和图片,爬了51.14G的视频。文章源自技术奇点-https://www.xerer.com/archives/18819.html
其中一个是通过搜索用户关系来添加ID,你只要知道你喜欢的某个用户ID就可以了文章源自技术奇点-https://www.xerer.com/archives/18819.html
给大家看一下最近爬的视频文章源自技术奇点-https://www.xerer.com/archives/18819.html
用Bitcomet做了种,可是不让放链接没办法。文章源自技术奇点-https://www.xerer.com/archives/18819.html
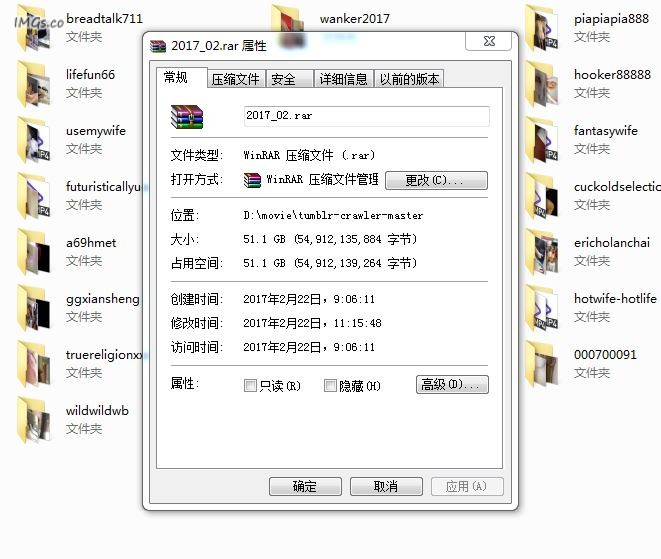
好人做到底吧! 链接就不放了怕违规,2017_02.rar老司机看到下面的图应该懂。解压密码为:流精岁月,(2017_02.rar Bitcomet解压密码)文章源自技术奇点-https://www.xerer.com/archives/18819.html
链接就不放了怕违规,2017_02.rar老司机看到下面的图应该懂。解压密码为:流精岁月,(2017_02.rar Bitcomet解压密码)文章源自技术奇点-https://www.xerer.com/archives/18819.html
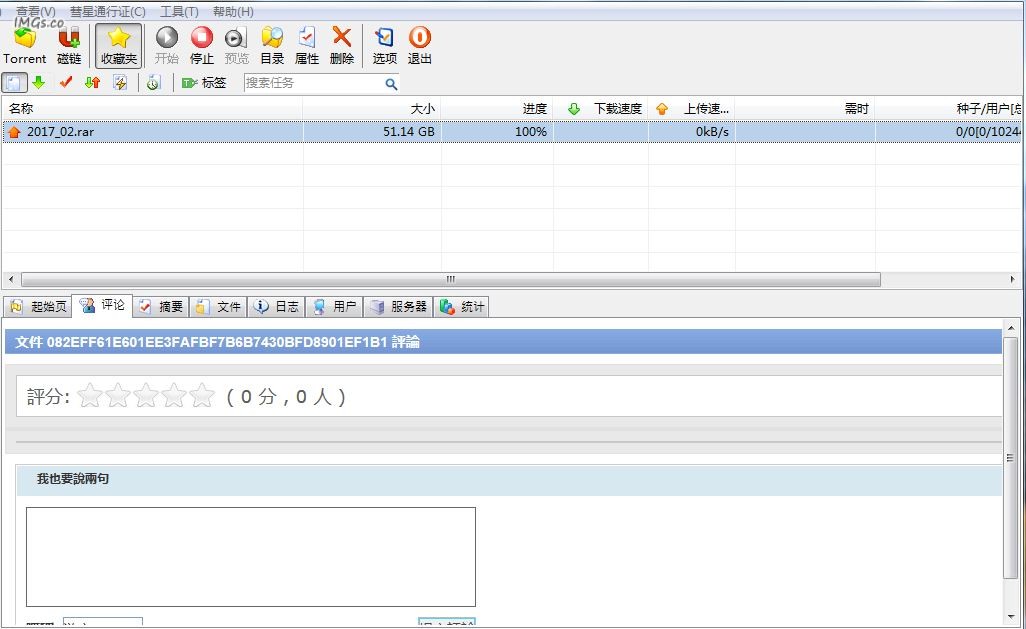
大家别再求链接了,邮箱已经爆满回复不过来,大家下载Bitcomet,然后输入下图中的特征码就可以了文章源自技术奇点-https://www.xerer.com/archives/18819.html
 文章源自技术奇点-https://www.xerer.com/archives/18819.html
文章源自技术奇点-https://www.xerer.com/archives/18819.html
以上内容纯兴趣,绝无广告,改天再发个技术贴,大家自己也可以折腾折腾!
做了一个教程 Tumblr--技术篇 文章如下
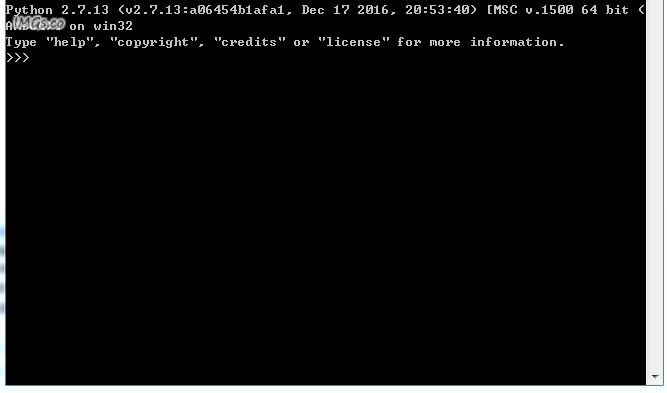
首先安装python 2.x环境(已经打包好,官网也有选对2.x版本),里面会自动安装PIP不要乱勾选,安装完后可能要重启电脑,然后在windows命令提示符下输入python验证一下是否安装成功,如下图示,不行的百度一下文章源自技术奇点-https://www.xerer.com/archives/18819.html
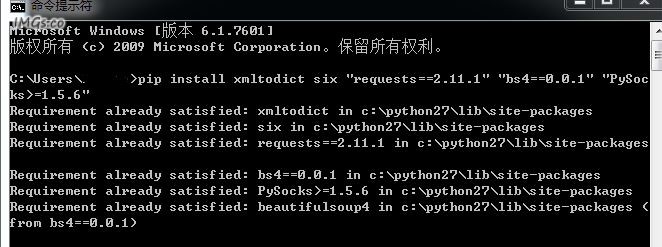
在windows命令提示符下用pip来安装Python的一些依赖包,把下面代码中的\都删掉,原来的代码里面没有,不知为何贴出来就多了\,我的是已经安装好的如下图示:文章源自技术奇点-https://www.xerer.com/archives/18819.html
複製代碼
pip install xmltodict six \\"requests==2.11.1\\" \\"bs4==0.0.1\\" \\"PySocks>=1.5.6\\"
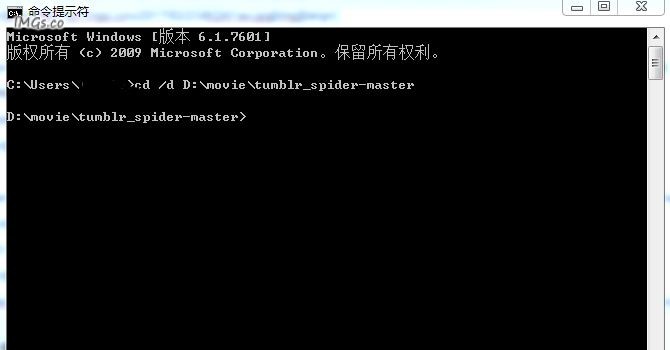
然后开始实战了,解压出两个爬虫包(帖子下面有特征码可以下载),打开并设置shadowsocks全局代理,在windows命令提示符下进入你解压的tumblr_spider-master文件夹内,代码中为何还是多出\文章源自技术奇点-https://www.xerer.com/archives/18819.html
複製代碼
cd /d D:\movie\tumblr_spider-master
这里的D:\movie\tumblr_spider-master是你自己的路径,每个人都有可能不同,然后输入文章源自技术奇点-https://www.xerer.com/archives/18819.html
複製代碼
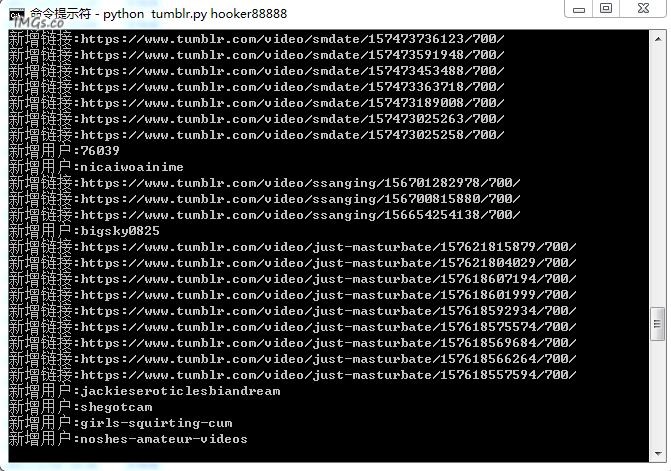
python tumblr.py username (usename 为任意一个热门博主的 usename)
user.txt 是爬取你喜欢类型的博主用户名结果(等下有用), source.txt 是视频地址集文章源自技术奇点-https://www.xerer.com/archives/18819.html
然后进入你解压的tumblr-crawler-master文件夹内将上面爬取到的博主ID填入sites.txt,最好每次填入一个ID我试过有时候不行,最多两个ID,用逗号隔开
如果你想下载该博主的所有图片和视频,直接点击tumblr-photo-video-ripper.py,如果只想下载图片或视频可以右键tumblr-photo-video-ripper.py Edit with IDLE 修改如下代码,在其前面加#注释掉
複製代碼
def download_media(self, site):
# only download photos
self.download_photos(site)
#self.download_videos(site)文章源自技术奇点-https://www.xerer.com/archives/18819.html
 文章源自技术奇点-https://www.xerer.com/archives/18819.html
文章源自技术奇点-https://www.xerer.com/archives/18819.html
複製代碼
def download_media(self, site):
# only download videos
#self.download_photos(site)
self.download_videos(site)文章源自技术奇点-https://www.xerer.com/archives/18819.html
运行之后你就会看到如下图示,爬取速度取决于你的代理服务器文章源自技术奇点-https://www.xerer.com/archives/18819.html
 文章源自技术奇点-https://www.xerer.com/archives/18819.html
文章源自技术奇点-https://www.xerer.com/archives/18819.html
文章源自技术奇点-https://www.xerer.com/archives/18819.html
爬取过程都要开启全局代理,开发者说可以建立proxies.json来使用代理有时候不成功,还不如开全局
以上内容都可以在github官网找到,分别搜索关键字tumblr spider ,tumblr crawler 搜索结果第一个应该就是,里面有详细的教程;我并不是原作者,我只是大自然的搬运工
最后附上要用到的工具,大家也可自行去官网下载。也可以留意评论版。
特征码:1067ed7b696185a3bcb7cf13d1d0213d8dd5989d
特征码:082eff61e601ee3fafbf7b6b7430bfd8901ef1b1文章源自技术奇点-https://www.xerer.com/archives/18819.html
文章源自技术奇点-https://www.xerer.com/archives/18819.html
